
The Framework
PufferLib is a high-performance reinforcement learning library written in C. It lets you train AI agents to play games at insane speeds, 1M+ steps per second on a single GPU.
You define an environment: what the agent can see (observation space), what moves it can make (action space), and how it knows if it's doing well (rewards). Then you let it play millions of games until it figures out a strategy. Speed is what makes PufferLib special, faster training means more experimentation.
I'm new to RL so take what I say with a grain of salt, but Joseph's streams made it look easy. PufferLib and I are becoming best friends... having way too much fun spinning up environments and watching agents learn.
WC3 Mazing Contest
If you're familiar with Warcraft 3 custom games, this is the Mazing Contest. You get a build phase where you place towers to create a maze, then a run phase with a "runner" you try to delay as long as possible.
It got good enough to beat me consistently but definitely not the better mazing contest humans.
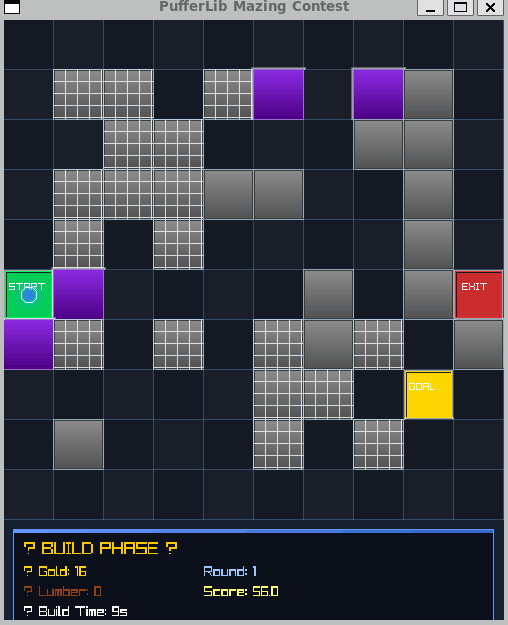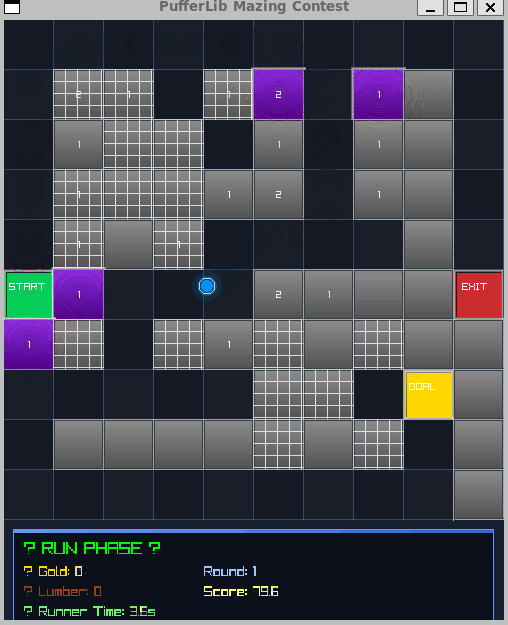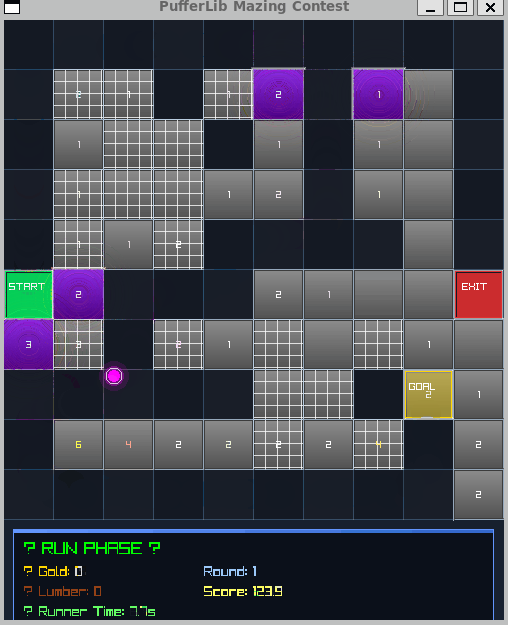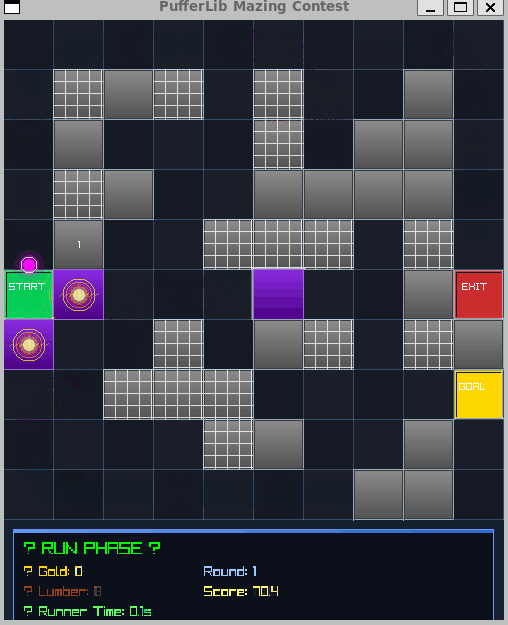
Best Rewards I Found
1. Average Path Length
Maximize the distance the runner has to travel
2. Maximizing Edges Touched
Hence the little numbers, best utilize each wall
3. Thunderclap Time Slowed
Small rewards for maximizing slow time
Tried many others (wall-touch penalties, efficiency metrics). The edges approach worked best.
UNDER THE HOODAction & Observation Spaces
Action Space: Discrete(200)
0-99 place walls, 100-199 place thunderclap towers. Grid encoding: position = y×10 + x
Observation: 108 floats
100-dim grid + 2 resources + 3 phase info + 3 goal info
Dual-Phase Design
BUILD phase → RUN phase (BFS pathfinding evaluates). Agent learns mazes that maximize traversal time.
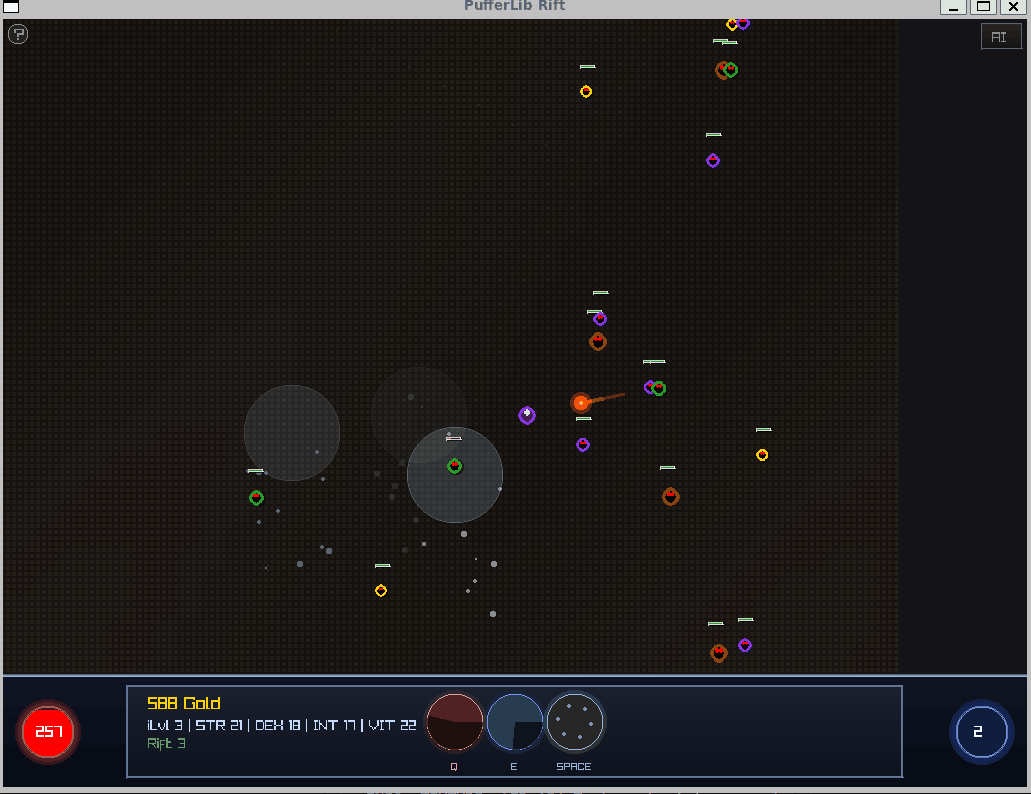
Rift: Roguelike Agent
Rift is a roguelike I built inspired by Diablo 3's rift system. You enter a rift, fight through scaling difficulty, then return to town to shop and equip gear before the next rift.
The agent needs to navigate, kill monsters, collect items, and survive. Pretty happy with battle performance but haven't fully verified shopping behavior yet.
Action & Observation Spaces
Context-Dependent Actions
Rift: 14 actions (8-dir movement + Blizzard + potions + interact). Town: 17 actions. Same IDs, different meanings per phase.
Observation: 223 floats
Player state (17) + 10×10 ego-centric grid (100) + town interface (101). Enemies encoded by threat level.
Progressive Difficulty
Per Rift: HP ×1.25, Damage ×1.18, Speed ×1.05, Attack CD ×0.95
The Observation Problem
I tried two ways to represent what the agent sees. Only one worked:
Local Grid
Worked10x10 ego-centric grid that moves with the player. Cells marked by entity type. Trained near instantly.

Entity List
FutureStore 10-20 closest entities with relative positions. Agent kept running into corners, missing wall info.
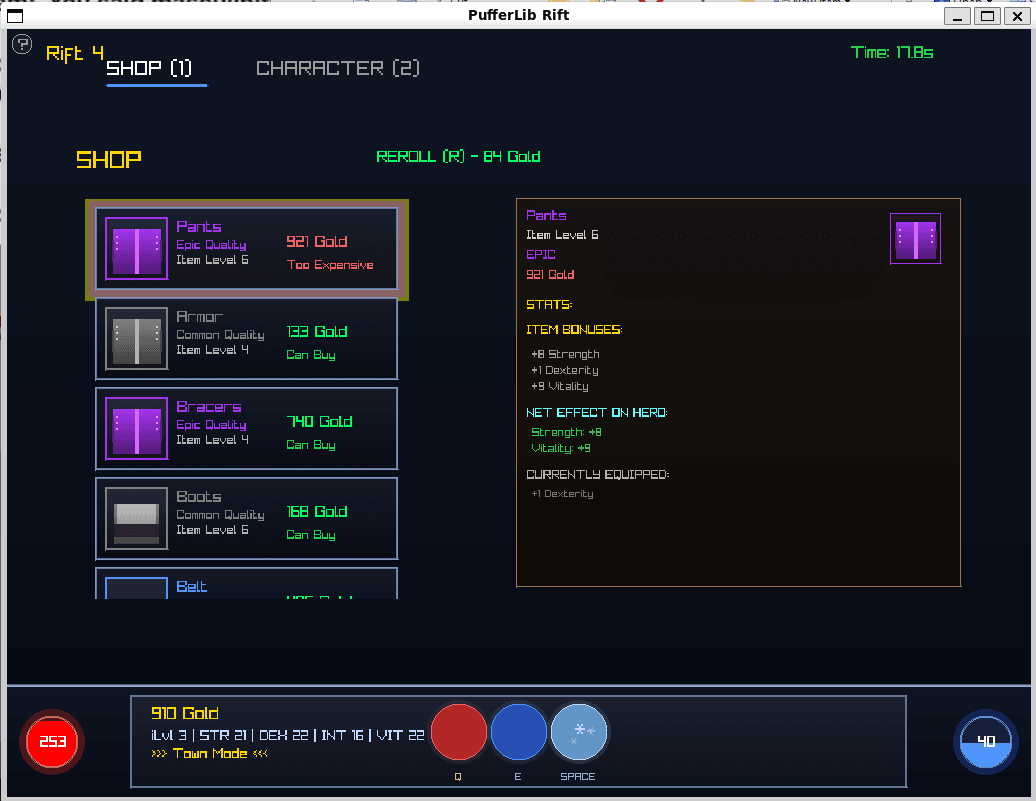
Shop
Reroll costs gold. Items randomly generated in different slots.
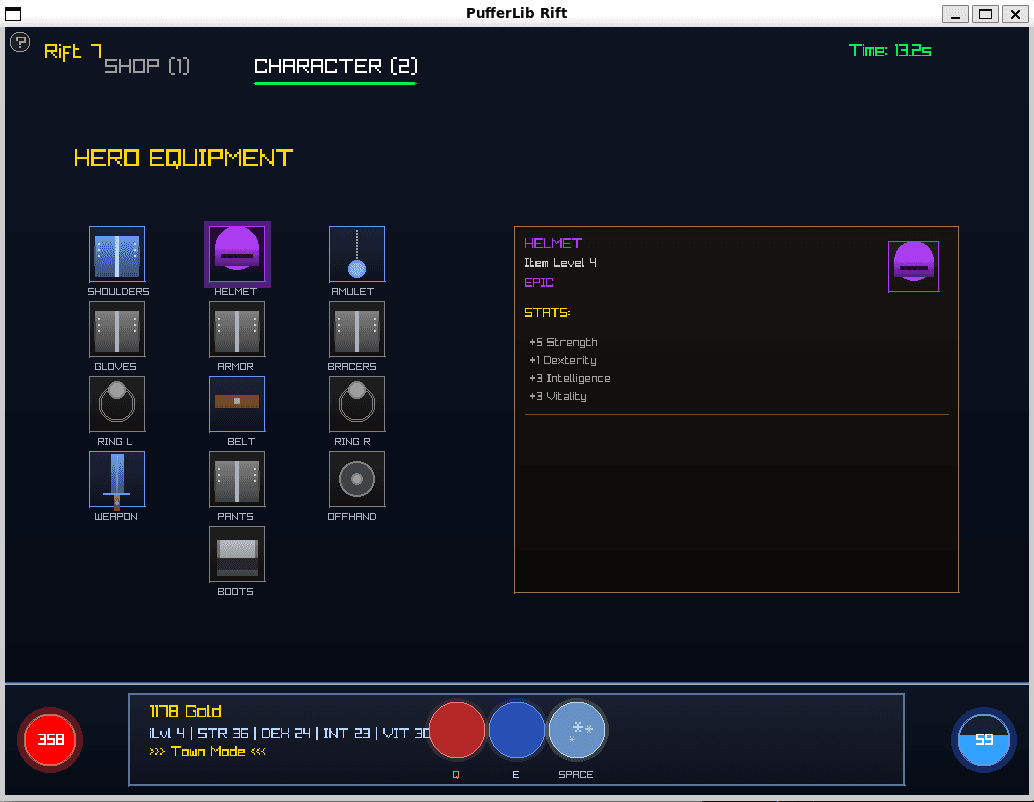
Equipment
Manage gear between rifts. Better equipment needed as difficulty scales.
Tower Defense
Classic tower defense, enemies spawn and walk a path. Agent learns tower placement and type selection to maximize kills.
Action Space: Discrete(577)
Each action encodes tower type + grid position. Invalid placements get small penalty (-0.1), agent learns constraints naturally.
Action 0: No-op
1-192: Normal Tower
Range 2, fast firing
193-384: Splash Tower
Range 3, AOE damage
385-576: Sniper Tower
Range 4, 2x damage
Observation: 7 Channels × 16×12 Grid
Ch 1-5: Tower, Enemy, Path, Gold, Valid Placements
Ch 6-7: Coverage Map + Enemy Density
Coverage = 1.0 - (dist/range). Density = Gaussian blur. These teach spatial awareness.
Balancing & Rewards
Agent initially chose Normal Tower 100% of the time. If one option dominates, it exploits it. Required several rounds of tuning cost, range, and damage until all towers became viable.
Reward function: kills + coverage bonus on placement. Removing coverage bonus made results worse, agent needs guidance on positioning, not just "kill things."
# Coverage bonus on placement
path_cells_in_range × 0.1
Speed variation (0.8x-1.2x per enemy) prevents synchronization exploits.


On Hold
Poker Self-Play
Texas Hold'em with agents playing copies of themselves. Currently too aggressive, not getting punished because opponents are equally aggressive.
This one's been humbling. Learning a lot about self-play training traps.
Hotel Simulator
Hotel management: check-ins, room assignments, resource allocation. Goal is max occupancy and happy guests.
Environment built, training not started. Interesting multi-objective optimization problem.
Parameter Tuning
wandb.ai is how I track experiments and run hyperparameter sweeps.
As a beginner I kept thinking I was optimized, then realized tuning parameters could get 3x to 10x more steps per second.
# All I changed...
[policy]
hidden_size = 32
[rnn]
input_size = 32
hidden_size = 32
minibatch_size = 65536
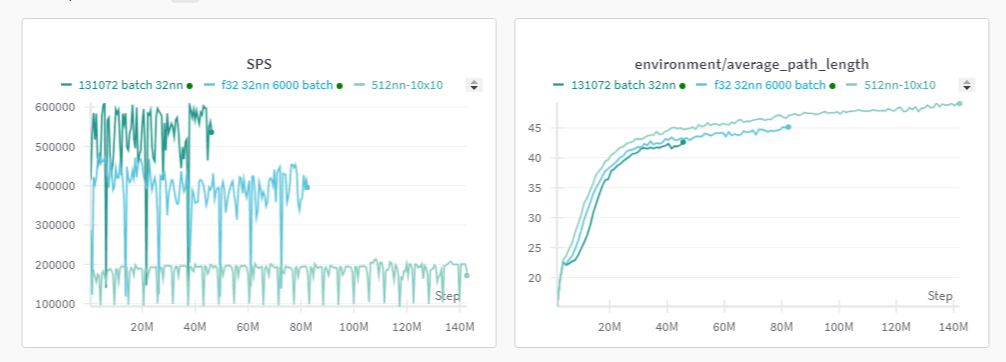
3-10x
Faster
66%
Overnight
30k→300k
Steps/sec
Sweeping is nuts, ran overnight and got 66% improvement. Thankfully puffer sweep helps a lot here.
Before vs After
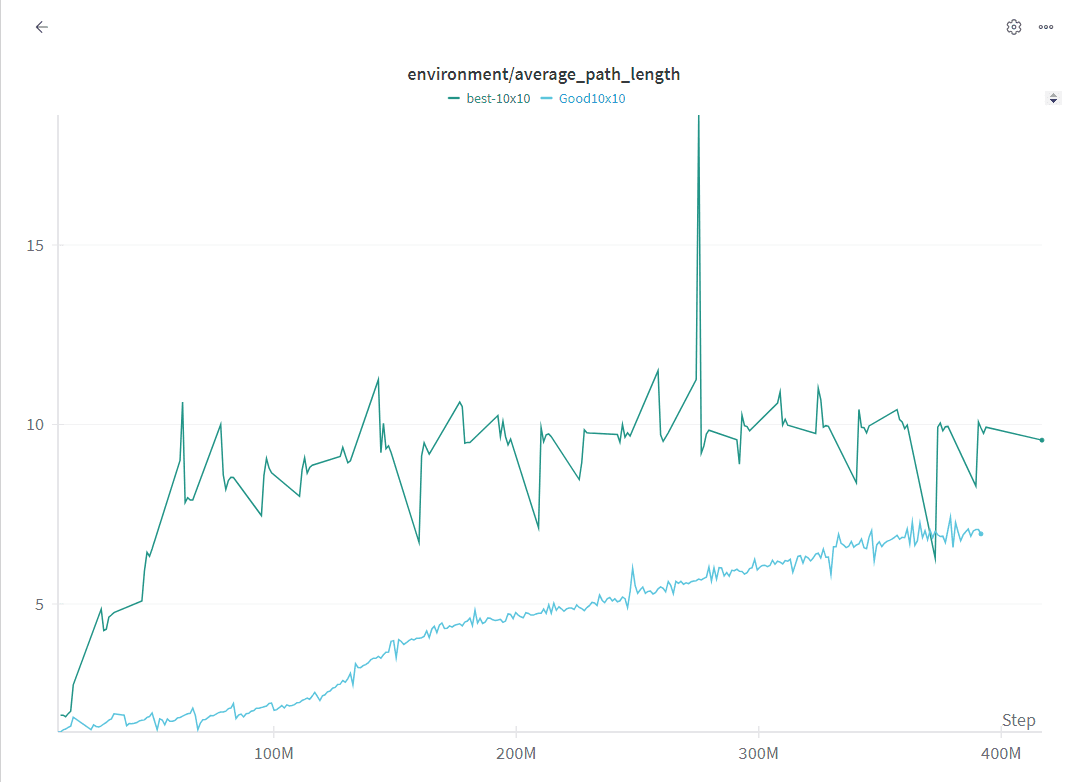
Overnight sweep
Wish I had multi-gpu to run more than 1 train at a time, but PufferLib lets contributors use their TinyBoxes.
Explore PufferLib
Thanks to Joseph Suarez for building this. If you're interested in RL, start here.